|
Keda Tao I'm Keda Tao, I am a first-year PhD student at Westlake University in a joint program with Zhejiang University, advised by Prof. Huan Wang. Previously, I received my B.E. degree from XDU in 2025. My research interests are multimodal large language models (e.g., VideoLLMs and OmniLLMs), Efficient AI, low-level vision, and generative models. I am currently a research intern at the Qwen Team, Alibaba Inc, focusing on the omnimodal understanding, agent, and video understanding. I am deeply grateful to my advisor and all collaborators for their guidance and support. Please feel free to reach out to me via email for any inquiries or potential collaborations. Email / ENCODE LAB / Scholar / Github |

|
🔥 News
|

📖 Publications |
|
arXiv 2026
|
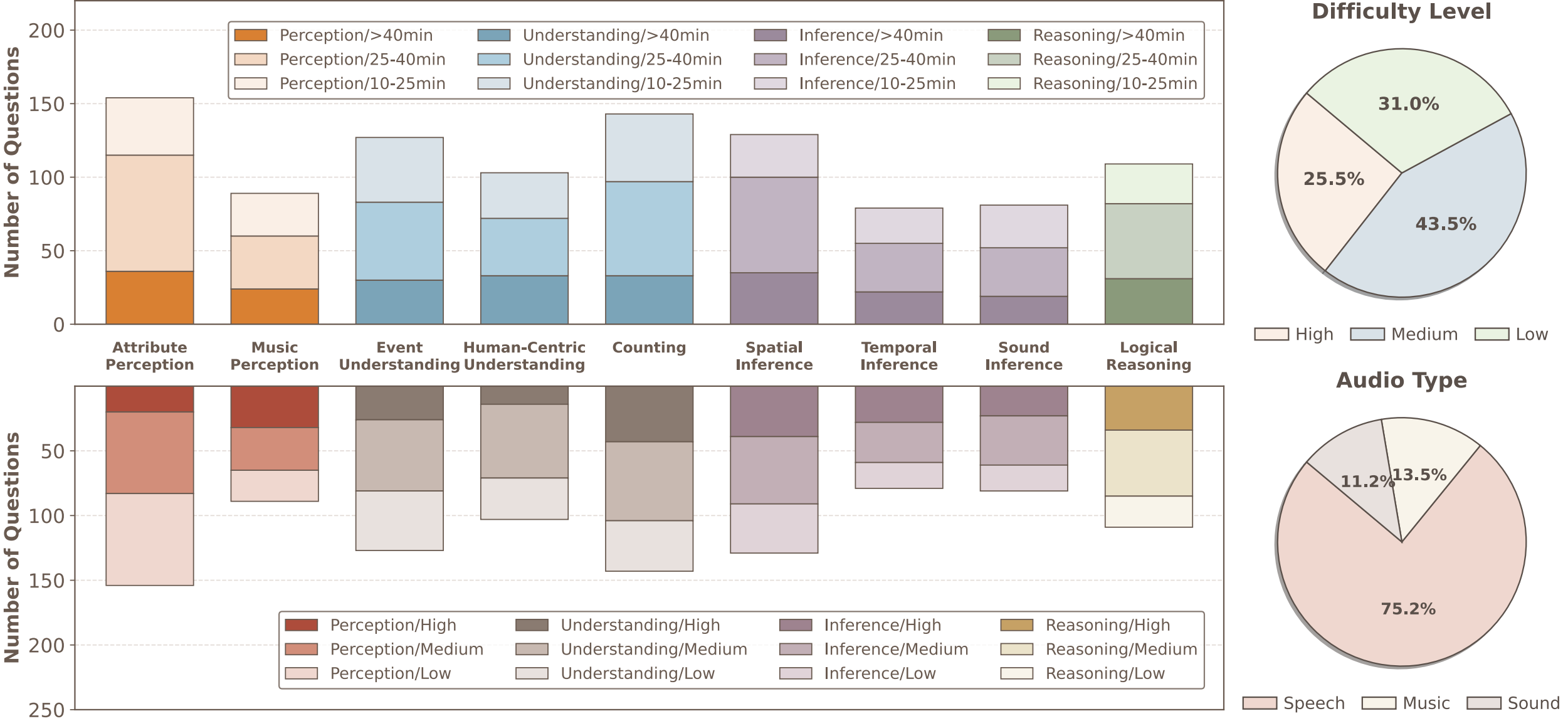
LVOmniBench: Pioneering Long Audio-Video Understanding Evaluation for Omnimodal LLMs
Keda Tao*, Yuhua Zheng*, Jia Xu, Wenjie Du, Kele Shao, Hesong Wang, Xueyi Chen, Xin Jin, Junhan Zhu, Bohan Yu, Weiqiang Wang, Jian Liu, Can Qin, Yulun Zhang, Ming-Hsuan Yang, Huan Wang
arXiv, 2026
|
|
arXiv 2025
|
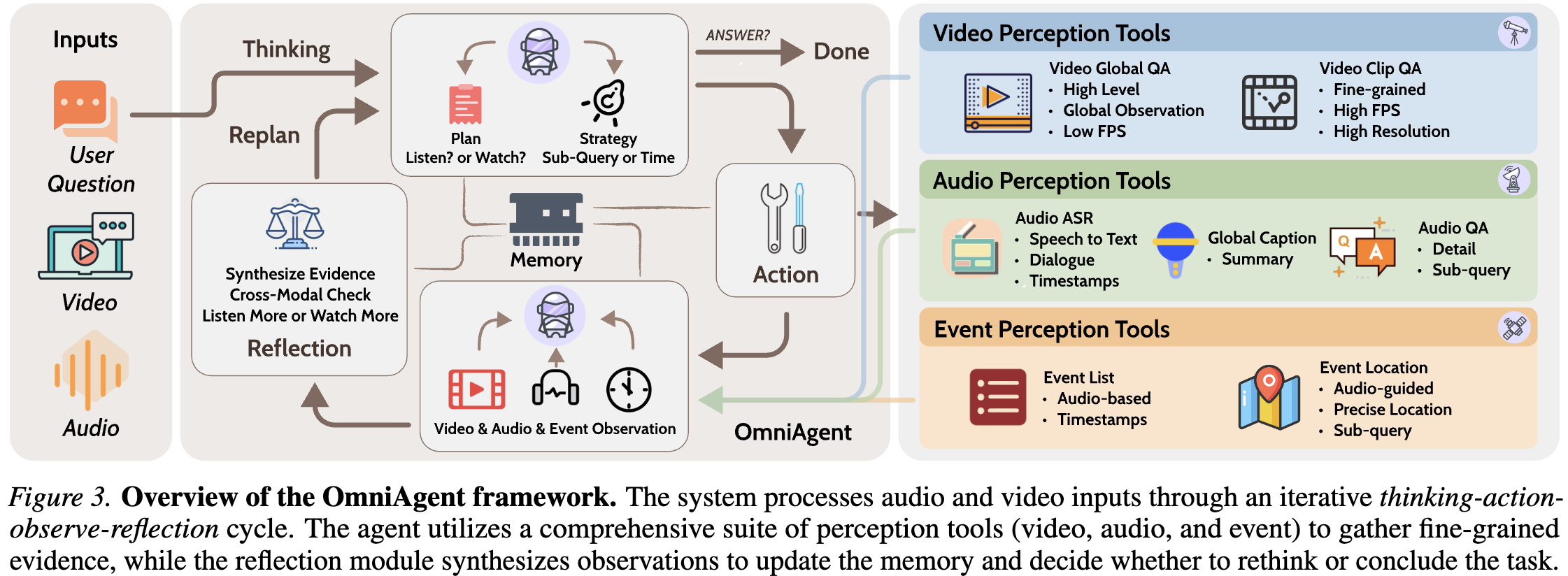
OmniAgent: Active Perception Agent for Omnimodal Audio-Video Understanding
Keda Tao, Wenjie Du, Bohan Yu, Weiqiang Wang, Jian Liu, Huan Wang
arXiv, 2025
|
|
CVPR 2026
|
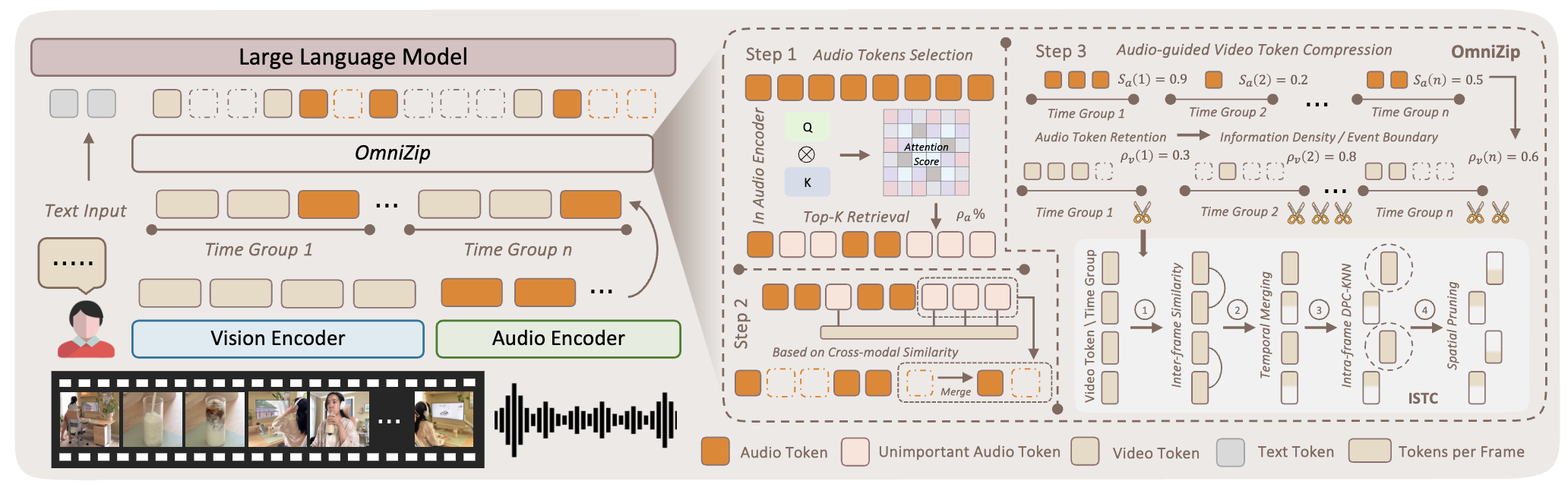
OmniZip: Audio-Guided Dynamic Token Compression for Fast Omnimodal Large Language Models
Keda Tao, Kele Shao, Bohan Yu, Weiqiang Wang, Jian Liu, Huan Wang
arXiv, 2025
[Project]
[Hugging Face]
|
|
ICLR 2025 Spotlight
|
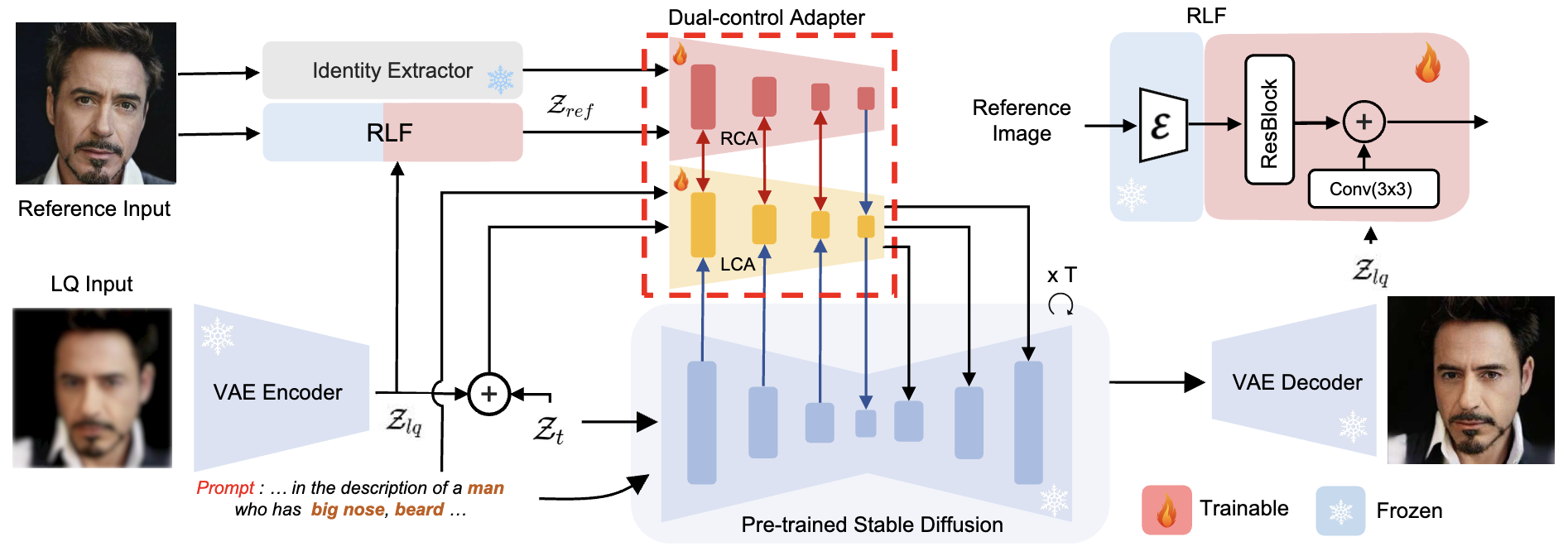
Overcoming False Illusions in Blind Face Restoration with Multi-Modal Guided Diffusion Model
Keda Tao, Jinjin Gu, Yulun Zhang, Xiucheng Wang, Nan Cheng
ICLR, 2025 (Spotlight)
|
|
CVPR 2025
|
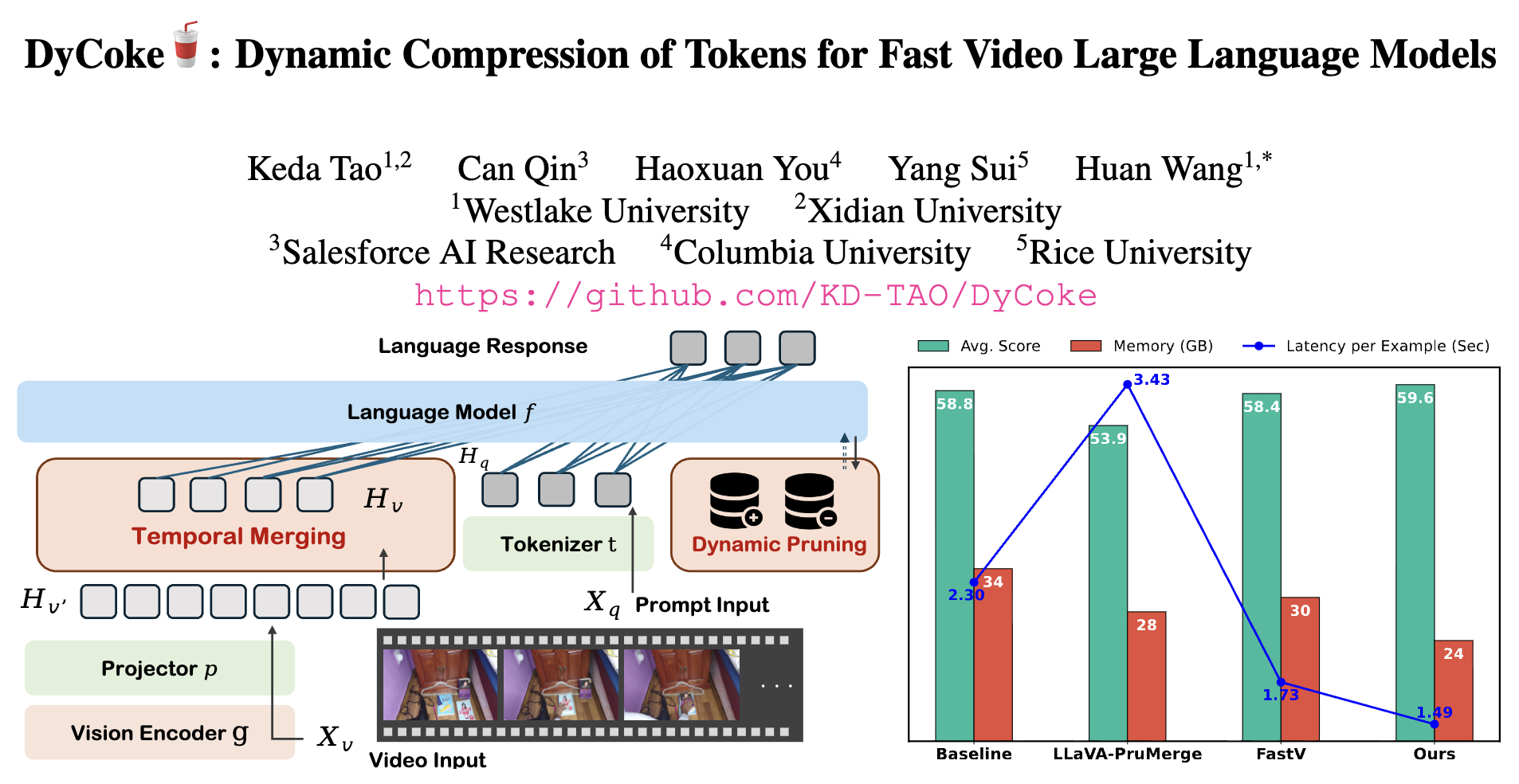
DyCoke: Dynamic Compression of Tokens for Fast Video Large Language Models
Keda Tao, Can Qin, Haoxuan Yu, Yang Sui, Huan Wang
CVPR, 2025
[Project]
[Hugging Face]
|
|
TMLR 2026
|
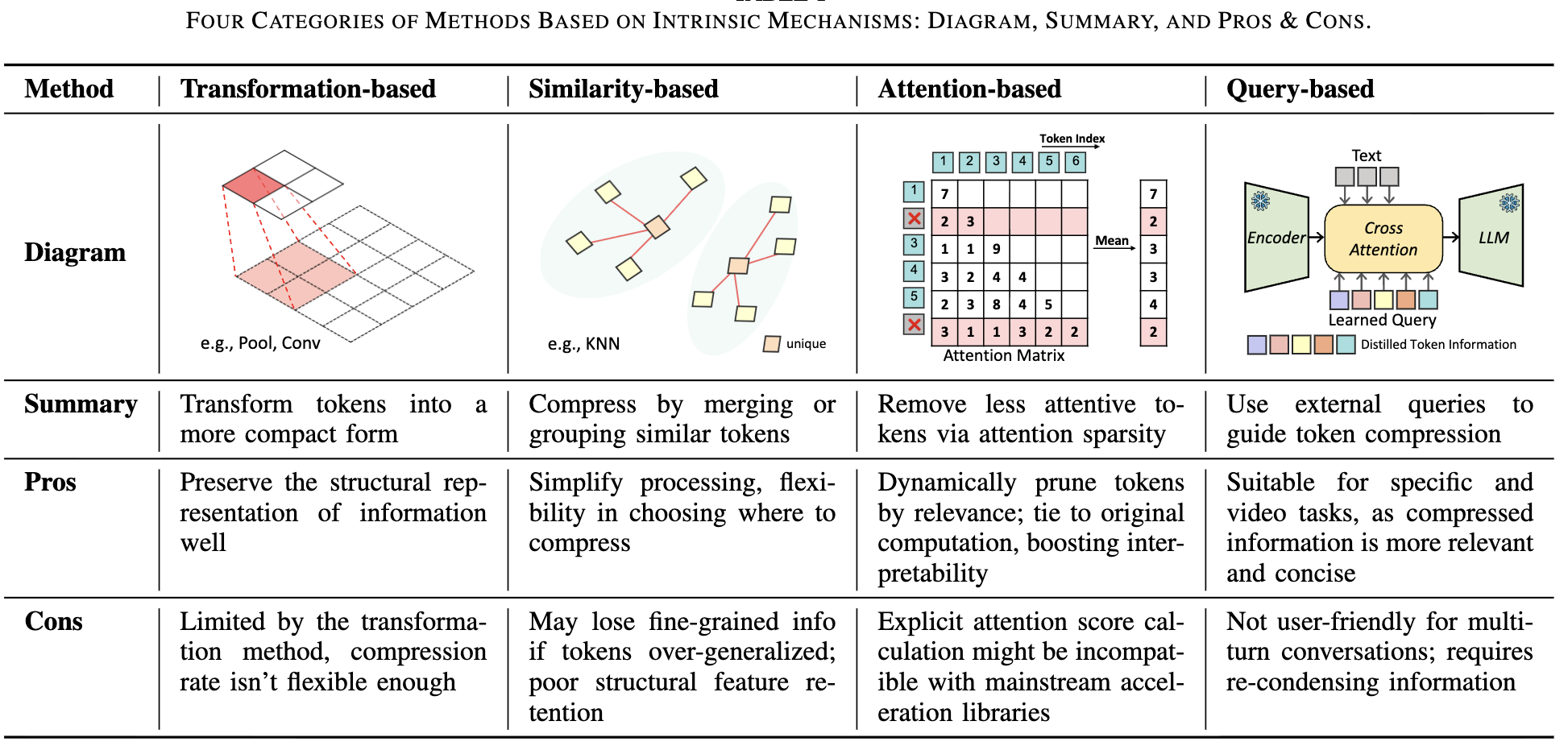
When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and Audios
Kele Shao*, Keda Tao*, Kejia Zhang, Sicheng Feng, Mu Cai, Yuzhang Shang, Haoxuan You, Can Qin, Yang Sui, Huan Wang
arXiv, 2025
[Project]
[Hugging Face]
|
|
Plug-and-Play 1.x-Bit KV Cache Quantization for Video Large Language Models
Keda Tao, Haoxuan Yu, Yang Sui, Can Qin, Huan Wang
arXiv, 2025
|
|
|
Poison as Cure: Visual Noise for Mitigating Object Hallucinations in LVMs
Kejia Zhang, Keda Tao, Jiasheng Tang, Huan Wang
NeurIPS, 2025
|
|
|
HoliTom: Holistic Token Merging for Fast Video Large Language Models
Kele Shao, Keda Tao, Can Qin, Haoxuan You, Yang Sui, Huan Wang
NeurIPS, 2025
|
|
|
StreamingTOM: Streaming Token Compression for Efficient Video Understanding
Xueyi Chen, Keda Tao, Kele Shao, Huan Wang
CVPR, 2026
[arXiv] [Project Page]
|
|
|
TARS: MinMax Token-Adaptive Preference Strategy for MLLM Hallucination Reduction
Kejia Zhang, Keda Tao, Zhiming Luo, Chang Liu, Jiasheng Tang, Huan Wang
arXiv, 2025
[arXiv]
|
|
|
Which Heads Matter for Reasoning? RL-Guided KV Cache Compression
Wenjie Du, Li Jiang, Keda Tao, Xue Liu, Huan Wang
arXiv, 2025
[arXiv] [Project Page]
|
|
|
RadioDiff: An Effective Generative Diffusion Model for Sampling-Free Dynamic Radio Map Construction
Xiucheng Wang*, Keda Tao*, Nan Cheng, Zhisheng Yin, Zan Li, Yuan Zhang, Xuemin (Sherman) Shen
TCCN, 2024
|
|
|
PhotoArtAgent: Intelligent Photo Retouching with Language Model-Based Artist Agents
Haoyu Chen, Keda Tao, Yizao Wang, Xinlei Wang, Lei Zhu, Jinjin Gu
arXiv, 2025
[arXiv]
|
|
|
Is Oracle Pruning the True Oracle?
Sicheng Feng, Keda Tao, Huan Wang
arXiv, 2025
|
|
🌟 Professional Services
|
|
This webpage is built upon the source code of Wenjie Du. |